
In a sense, COVID-19 could be the perfect story to automate. As the virus spread across the world at the beginning of 2020, governments and health authorities made a considerable amount of open-source data available to the public, such as the number of deaths, patients in intensive care units, and seven-day incidence rates.
This type of well-arranged data, which can fit into narratives that can be created in advance, lays the groundwork for a recent journalistic development known as “automated journalism,” a computational process that creates automated pieces of news without any human intervention, except for the initial programming.
Automated journalism generally implies the use of algorithms that fetch information on external or internal datasets, and then fill in the blanks left on templates that have been prewritten. This process, which can be compared to the word game Mad Libs, constitutes a basic application of Natural Language Generation, a computer technique that has been around for several decades in domains such as weather forecasts, sports and financial results.
NLG made a leap into journalism and was more widely discussed in the first half of the 2010s as The Los Angeles Times used automated text to report on homicides and earthquake alerts, while The Associated Press partnered with the firm Automated Insights to automate stories on corporate earning. Numerous media organizations have subsequently adopted or experimented with automated journalism, including major ones like Le Monde, The Washington Post and the BBC.
In-house, outsourced or third-party
Proponents of automated journalism typically develop their technology in-house, outsource it to an external content provider such as Syllabs in France and Narrativa in Spain and in the United States, or use third-party solutions so that journalists can design their own automated news, as it is made possible through Automated Insights’ Wordsmith and Arria NLG Studio.
Automated news can then be published simultaneously at massive scale or used as first drafts to assist journalists with their own writing.
In my report for the Tow Center, I documented the experiences of nine media organizations that have used automated news for reporting on COVID-19. I found that most organizations used them to provide a statistical overview of the spread of the virus, through user-facing interfaces and new media products.
For instance, Swiss media company Tamedia and The Times (United Kingdom) featured national and international dashboards that summarized the latest COVID-19 data with automated text, along with a great many automated or semi-automated graphics.
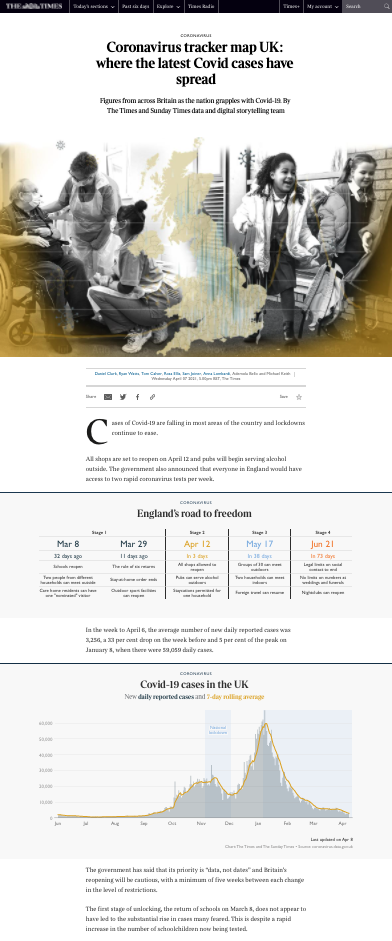
A screenshot of the COVID-19 tracker page at The Times. It features automated text and graphics that give a breakdown of the latest coronavirus statistics in the United Kingdom. (Courtesy: The Times)
I also found that some organizations deployed new forms of newsroom workflows, where journalists contributed to the creation of automated news or worked directly with them.
At the British news agency RADAR, a new form of workflow where journalists are involved all the way into the process of setting up automated news — from finding storylines in newly published datasets to authoring templates using a third-party tool — demonstrated to be robust enough to handle the data deluge that followed the spread of the virus.
At the Finnish newspaper Helsingin Sanomat, an algorithm set up by the data team fetched new COVID-19 numbers on a governmental API, so as to generate short pieces of text that were sent to Slack to inform reporters. They could then decide to publish these as-is or tweak them before publication.
Challenges of relying on external datasets
In my report, I also illustrated some of the challenges that newsrooms faced when using automated news to cover COVID-19. Overall, these demonstrated the difficulties associated with having to rely on external datasets.
This was most notably the case with newsrooms trying to get data from several levels of government.
In Canada, a journalist-developer at the Canadian Press said that it was hard to get COVID-19 data from multiple governments: “They all put it up in a different fashion, they put it up at different times,” he said.
In the United Kingdom, The Times grappled with the same lack of cohesive efforts: “England, Scotland, Wales, and Northern Ireland all publish it in different ways,” said a data and interactive journalist at the newspaper, adding that this made comparisons between regions even more difficult.
In Norway, the news agency NTB faced an even bigger challenge: “Every Norwegian municipality has a different way of providing the data on their own pages. So it’s like 356 municipalities, and they have 356 different ways of sharing the data,” said a chief development officer at NTB.
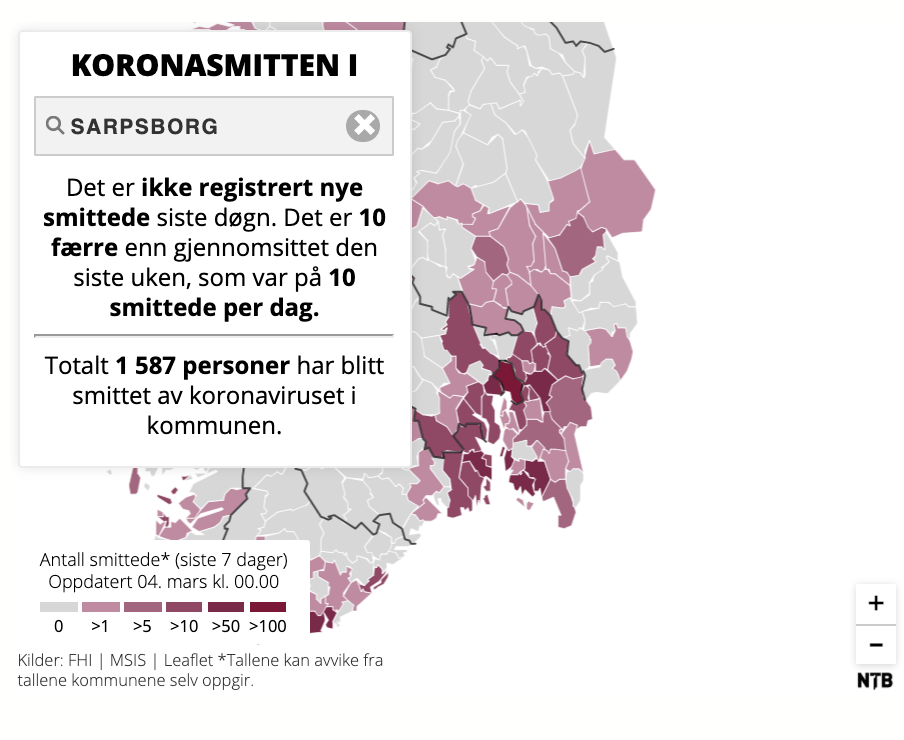
An example of an automated map on COVID-19 that NTB generated. NTB’s automated stories included health-related statistics, but also unemployment and furlough figures caused by the pandemic. (Courtesy: NTB)
Another challenge of relying on external datasets to automate COVID-19 stories had to do with erroneous data and sudden changes of format.
First, data published by health and governmental bodies could prove to be inaccurate. “Sometimes the data has been wrong and they’re not corrected,” said an editor at NTB. This could be even more problematic when it concerned the number of patients who have died from the virus.
Second, sudden changes of format were also considered to be a major obstacle in automating the coverage of the virus. For instance, the data team at Helsingin Sanomat experienced difficulties with some data being released in an HTML table format. A data journalist explained that the table’s structure kept changing all the time, for instance when the number of patients hospitalized was being moved from one column to another, making it very hard to use for automated news.

Above: HS sends automated text to journalists through Slack, to include wholly or partially in their copy. (Courtesy: Helsingin Sanomat)
Finally, releasing data too soon or too late also came into consideration when working with external datasets to generate automated news on the spread of the disease.
Some media organizations occasionally reported a lag in releasing data on the pandemic, resulting in numbers accumulating over a few days before being published all at once with more up-to-date data. “In today’s numbers, they might publish some deaths for a week ago,” said an editor at RADAR, who cautioned that reporters then needed to be extra careful when reporting differences between each of these dates.
On the other side of the coin, news organizations could also get the latest COVID-19 numbers before any official announcement, while connecting to an API service set up by governments or health authorities. “Sometimes we have actually managed to kind of beat, so to speak, the local health sources on their own news,” said a managing editor at Omni, a Swedish news service that used an automated dashboard connected to these kinds of sources.
Adopting a computational mindset
To overcome the challenges of having to rely on external datasets to cover COVID-19 with automated news, media practitioners with a strong computing background at some of the organizations that I’ve studied developed ad hoc solutions to work around those.
To deal with data being released in various time zones, the Canadian Press set up an advanced shared spreadsheet system that involved the participation of journalists in all Canadian provinces and territories, while The Times and Helsingin Sanomat developed an alert system to work around tight deadlines and sudden changes of format.
All in all, these ad hoc solutions demonstrate the importance for media practitioners to be able to solve problems through applying computing skills, a form of knowledge commonly known as computational thinking or computational journalism in a newsroom setting.
This type of mindset has given journalists a considerable edge in deploying automated news quickly and efficiently in the midst of a global pandemic, but may also fuel ideas for the next iteration of these products.
Although the template-based approaches are sometimes criticized for being too formulaic and less enjoyable to read than human-written news, they can at least be tweaked to achieve editorial goals. The more media practitioners engage with this tinkering of automated news systems, the more they develop their programmatic skills and thus reinforce their ability to exert control and have a say over the computational turn that journalism is taking.
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 765140.




